O sinal de hoje não é um modelo mais esperto.
É um modelo que aguenta operar por mais tempo.
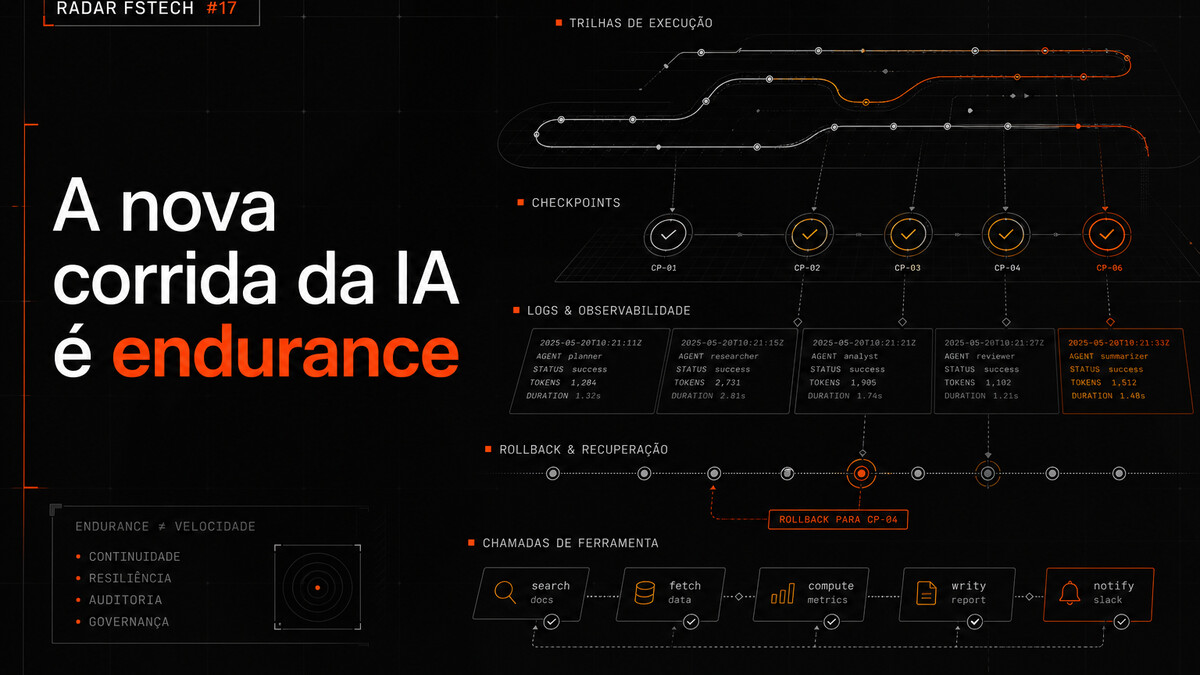
1 milhão de tokens. 35 horas de autonomia. 1.000 chamadas de ferramenta. Planos comentáveis. Rollback automático. Benchmarks mais próximos do trabalho real.
A pergunta mudou. Não é qual modelo responde melhor. É qual sistema continua confiável depois da centésima ação.
Leitores do Radar
Nem todo mundo quer mais conteúdo sobre IA.
Algumas pessoas querem critério.
... leitores já acessaram esta edição do Radar FSTech para separar sinal de ruído no universo da inteligência artificial.
Se você é uma delas, assine o Radar ou compartilhe com alguém que também deveria estar aqui.
SINAIS DE HOJE
1. Qwen3.7 Max entra na corrida da autonomia longa.
Alibaba colocou o Qwen3.7 Max com 1 milhão de tokens de contexto, 80.4% no SWE-Bench Verified e até 35 horas de execução autônoma com mais de 1.000 tool calls.
→ Contexto longo sem governança é só uma memória grande demais para auditar. O diferencial é saber o que o agente fez, por quê, com qual permissão e com qual rollback.
2. OpenADE transforma agente de código em fluxo governado.
A Bearly AI lançou o OpenADE com suporte a GPT-5.5, Codex e Claude Code. O padrão importa: tarefa, plano por arquivo, comentário, refinamento, escopo travado, execução e snapshots Git.
→ Isso é Pin/Spec aplicado a coding agents. Antes da ação, plano. Durante a ação, diff comentável. Depois da ação, snapshot e rollback.
3. DeepSWE mostra que benchmark fraco esconde diferença real.
A Datacurve lançou um benchmark com 113 tarefas em 91 repositórios, cobrindo TypeScript, Go, Python, JavaScript e Rust. A tese é simples: benchmarks antigos ficaram pequenos, contaminados e fáceis demais.
→ Avaliação boa precisa parecer com trabalho real. Código legado, contexto incompleto, múltiplos arquivos, critério de aceitação e falha possível.
Hassabis disse que ainda faltam memória, consistência e aprendizado contínuo para AGI.
O mercado está tentando resolver isso na prática: contexto maior, sessões mais longas, agentes com plano, benchmarks mais duros.
O próximo salto não é só inteligência.
É endurance com governança.
Modelo que aguenta. Sistema que verifica. Operação que registra.
Se algum desses sinais toca um processo real da sua empresa, o próximo passo não é colocar mais IA em cima do caos. É mapear Dados, Lógica e Ação. Comece aqui.
MATÉRIAS ORIGINAIS
Qwen3.7: The Agent Frontier
OpenADE: Agentic Development Environment
DeepSWE: benchmark para coding agents
Demis Hassabis on AGI and AI for science
